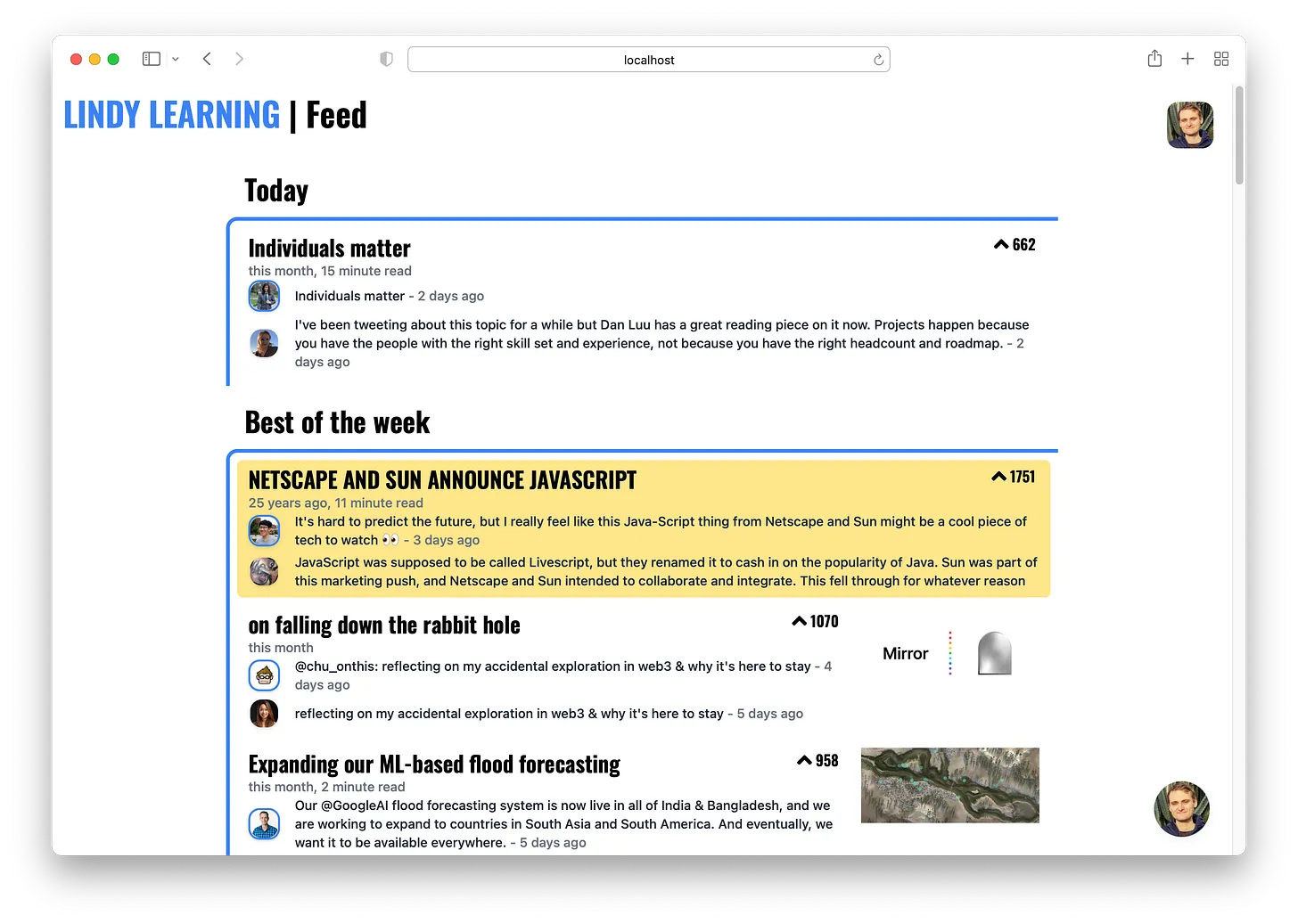
Evergreen content gardens
A year ago in Feed Overload I wrote:
99% of all microblog (and chat) content is ephemeral by design, meant for a specific moment in time. But the 1% that should endure past the 24hr cycle doesn't have good ways to do so in the current paradigm.
Reddit/Lemmy has a simple Top sorting mechanism for viewing highly rated content in the past Day / Week / Month / Year / All Time. This is a great way to surface evergreen knowledge artifacts in places like r/AMA and r/todayilearned. It's also a very helpful way to get oriented in a new space.
The same could be done for hashtags on the fediverse. Treating hashtags as not just timelines of the present moment but also containers of institutional knowledge could lead to all sorts of innovations in knowledge management on the fediverse.
I explored some tangents along that trail in Follow Anyone and Sense-making on the fediverse. Today I’m continuing down this path, refocusing on the notion of content gardens, spurred on by two new developments.
First, a new type of links-curation app was announced: Introducing linkblocks, the Federated Bookmark Manager.
Then yesterday a developer I follow on the fediverse mused about a knowledge-sharing app in the same vein:
I'm thinking about working on a new platform for reading stuff on the web. To launch, I want a RSS reader (like miniflux; feedly) and a bookmark manager (like pinboard; pocket) with tight integration between the two and opt-in community features. I will eventually extend to stuff like annotation.
I’m particularly interested in the Pinboard-like experience. Prior to all of the all of my blog posts linked above, I wrote an experimental piece called Netizenship from first principles wherein I try to imagine a safe on-ramp to the internet for my 7yr old nephew.
I think I’ll rewrite it one day as I never felt like it fully arrived at its intended destination, but it presents a trio of magical applications that I still consider to be a great foundation for sense-making on the web:
- 🪪 an ID card you can never lose, to safely make your self known on the web.
- 👜 a bottomless Bag of Knowledge, for storing and synthesizing the wealth information you come across on your journey.
- 🌐 a telepathic Study Group, to connect with other learners and exchange resources as part of a knowledge-gardening collective.
There’s more than one application catering to each of these archetypes. They’re not necessarily divided in three either, but personally I prefer that delineation.
For my purposes, Weird will cover the 🪪ID card and Omnivore already covers the 👜Bag of Knowledge. The missing piece is the 🌐Study Group, and that’s where Linkblocks comes in.
Social knowledge network
I think Linkblocks is still figuring out its identity and I don’t intend to direct it one way or the other, so what I’ll be talking about here is how I personally imagine and want a web application like Linkblocks to behave.
The social bookmarking app archetype has been around for decades, popularized by Delicious and carried as more of an indieweb phenomenon by the likes of Pinboard.
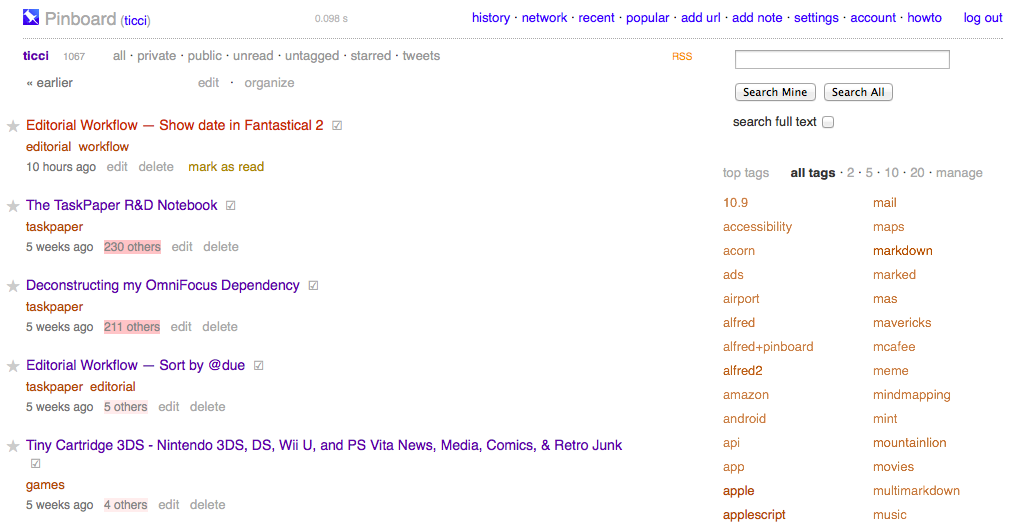
It bears a striking resemblance to Reddit, which is no accident. Reddit, like its forebearer Digg, was a subsequent iteration on the links-aggregator concept, but with one crucial difference: Rather than leaning into the timelessness of social bookmarking, the Reddits and Diggs of the world were social news websites, which are different beasts entirely.
Reddit is all about the *now*; viral trends of the day. Pinboard’s quiet indie success has been in the *timeless*, the evergreen nature of content without an expiration date. It’s not about *when* links are added, it’s all about how many people have the same link in common, and what tags-of-meaning they’ve applied to them. Commenting is also entirely optional in the links garden, instead endorsing a digital form of parallel play.
What all of these apps do have in common is the function of a links aggregator. It is therefore conceivable that what Linkblocks is doing could just as well be accomplished with the similarly Rust-based Lemmy for instance. In a world of more architecturally modular applications I think that would be quite possible, but as things are I think the DNA of Lemmy as a Reddit-like is too deeply embedded for the notion of timelessness to fully take root and thrive there to its fullest.
Newspapers and books are made of the same exact stuff – paper, ink and words – yet their distinct form factors make all the difference in how we treat them as either ephemeral or long-term stores of knowledge.
Reading vs sharing
Having talked about the different types of link aggregators, let's now draw a line between the two categories of read-it-later apps, also commonly known as bookmark managers.
As I see it, the difference lies between applications for reading and sharing. A secondary separator can be gleaned between private vs public.
- Omnivore, Wallabag, Shiori, Linkwarden: Optimizes for the reading experience, practiced almost exclusively in private.
- Pinboard, Linkblocks, Linkding: Primarily enables a sharing experience, practiced partially or fully in public.
For the latter bunch the app-makers themselves might disagree with me, but I think their capability for public sharing puts them in a distinctly different category than the former bunch. The combination of social-sharing and publicly readable content makes those applications more closely related to the links aggregators of the ‘social media’ variety. And yet, not quite that either.
Communal links gardening
Here’s a live example of Linkding as a public listing of links on someone’s personal webpage.
That app is a mature example of what Linkblocks might grow up to be, though given its ambitions as a federated bookmarks manager my hope is that linkblocks will more fully embrace the magic of sociality.
Considering what the read-centric applications already do well, linkblocks would be wise to focus its efforts on sharing:
With linkblocks, you can do three things: You can bookmark what you find on the web, you can structure your bookmarks, and you can exchange bookmarks with other people.
It’s only that last thing that I currently lack a good tool for. A narrow focus on the public exchange of links lends itself well to a series of other novel features, like collections:
Curated collections
I’d like the ability to create curated lists of roughly the same kind as what you’ll find on IMDB: https://www.imdb.com/list/ls055592025/
One way to do it would be to allow lists based on tag combinations, e.g.:
burnout + open-source
https://mikemcquaid.com/open-source-maintainers-owe-you-nothing
https://nolanlawson.com/2017/03/05/what-it-feels-like-to-be-an-open-source-maintainer/
https://medium.com/@mikeal/time-to-leave-a68294ccb2af#.p8ss5xeqz
The key difference from having a bunch of articles with a certain tag is that a Collection can optionally have an order added, to say “read this before that”. That way you’ll have an additional data point that can be used to arrive at a global list of the top3/top5/etc. #burnout+#opensource articles.
I’ve started this feature discussion on the linkblocks repo.
Automated collections
I run two chat spaces for my Spicy Lobster and Commune projects. Both of these spaces have accumulated hundreds of links at this point.
We can imagine an automated collection of ‘Commune links’ by simply passing any link added in that chat onwards to Linkblocks, already tagged with whichever channel it was posted to. Additional tags and ordering can be added from there, for example by tagging some links as “essential” and others as “advanced”.
New paradigm
Social bookmarking is a novel use case for ActivityPub and I’m super excited about it. I heckin’ love links and lists. I wanna use them for everything.
Things like Bookwyrm are cool, but it’s not what I want. I just wanna link the thing. Books, films, podcasts, articles, songs.., they’re all just resource recommendations which can be encapsulated by links. Good Stuff, as Linkblock’s Rafael puts it.
I don’t wanna write reviews and rate with stars. I hardly even wanna do a search. I just wanna know who else in my network is interested in the same stuff, and have new stuff recommended to me that way. A local-first, relatively old-fashioned recommendation engine, subtly supercharged with online connectivity.